What is a Log File Monitor
A log file monitor is a utility designed and built specifically to monitor and alert on messages produced by computer systems and the applications that run on them.
In UNIX, the monitoring of log files is absolutely necessary, and for good reason. You see, the time of a Unix Professional is valuable. Few, if any, can afford to spend hours each day scouring through the many log files that are generated by systems and network applications. However, if you fail to quickly recognize the abnormal or fatal events chronicled in these log files, entire networks can be abused and/or removed from service....which can cost your company dearly, monetarily speaking.
If you wish to monitor log files, there are basically [ 3 ] options available to you:
- You can try writing your own log monitoring script and see how far that takes you (this is worth looking into if you only have a couple of logs to monitor)
- Download any of the FREE log monitoring scripts that are available all over the internet OR
- Purchase a professional tool that was developed specifically for situations like yours and that can easily accommodate future customizations, if necessary
If you embark on a journey to write your own script, you have to understand that it will be an endeavor that will take years to complete, and that's assuming you're a skilled programmer. Monitoring log files goes far beyond simply watching the contents of files for specific errors. As time goes on, there will be new requirements, changes, and continuous requests for modifications which in the end, if the developer isn't creative, can lead to an unusable script - one that is not user friendly.
If you choose to download the FREE log monitoring scripts that are available on the internet, you will quickly discover how ineffective they all are and how much work is necessary to get them to cooperate. If this is the option you choose to go with, you must ask yourself some very important questions:
- Will I be able to easily administer the creation and modification of several log checks (from a central location) using this method?
- Is this method scalable?
- Can I use this one method to monitor different logs on several hundred servers, or am I going to have to do a lot of configurations, compilations, installations, tweaking etc?
The answers to these questions are usually quite depressing. Proceed with caution.
Characteristics of the Ideal Log Monitor:
When searching for the right utility to use to monitor & alert on log files, what features should the perfect tool have?
The ideal log monitor must be able to scan and monitor log files in a very short period of time, preferably in seconds (no matter how big the log file is). At the very least, the perfect log monitor must be able to:
- Detect abnormal usage patterns in log files
- Recognize system or network abuse (through mathematical analysis of data)
- Detect vulnerability scans (e.g. port scans) through the use of user-specified patterns
- Detect intruders or attempted intrusions (through the use of user-specified patterns)
- Detect resource shortages (e.g. slow response times, out-of-memory conditions etc)
- Detect imminent application and system failures (this is usually in some log file on your system)
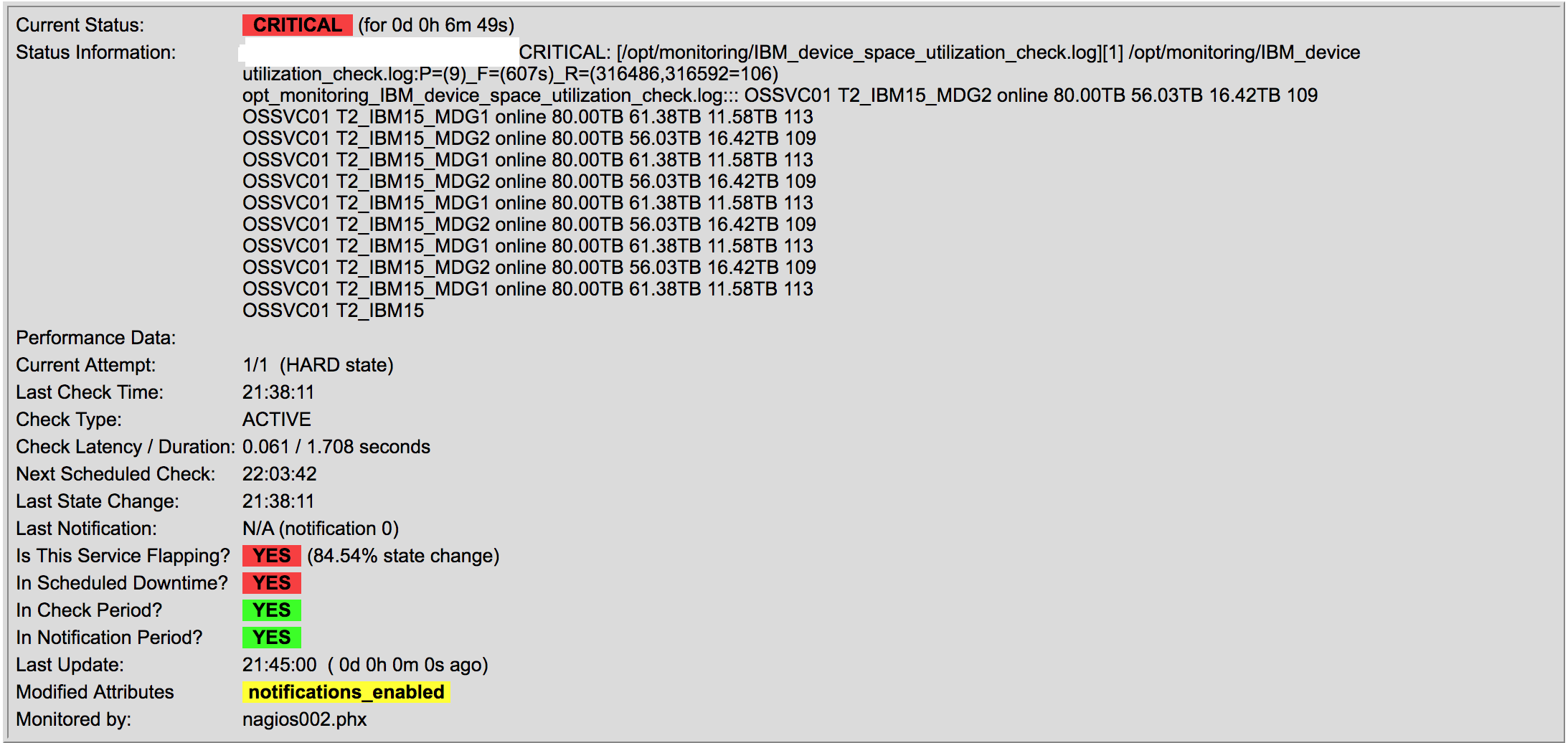
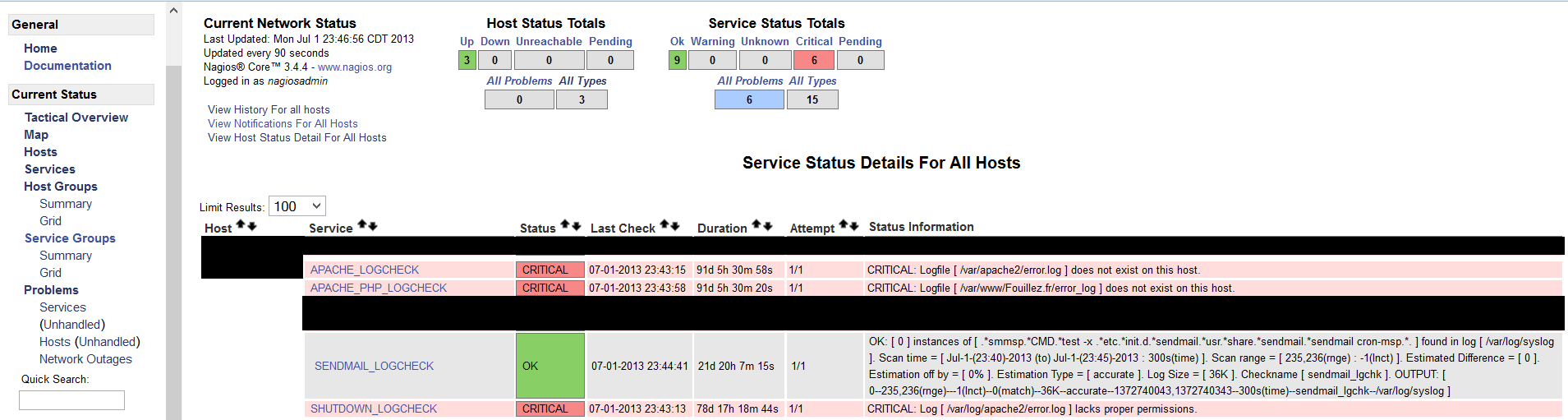
- Scan, monitor & alert on log files of different formats (this is absolutely crucial)
While each feature listed here is important, it is worth noting that above all else, the perfect log monitoring utility must be easy to use. Users SHOULD NEVER have to spend too much time reading documentations before being able to utilize a software. The more complex a utility is, the more likely it is to be used the wrong way or abandoned altogether. Imagine having to re-read the Instruction Guide of your Television remote control each time you wanted to use it. Can you picture the annoyance of that?
When it comes to log monitoring, ease of use is essential. I cannot stress this enough. The developer(s) must focus a great deal of effort into drastically limiting or eliminating the need for configuration files. Also, the syntax of the tool must be easily comprehensible and applicable directly from the command line. This means, if a random user were to run the tool from the command line, there shouldn"t be room for confusion. That user should be able to conveniently obtain whichever end result he/she was expecting WITHOUT having to read several pages of complex documentations or desperately scouring Google for help!
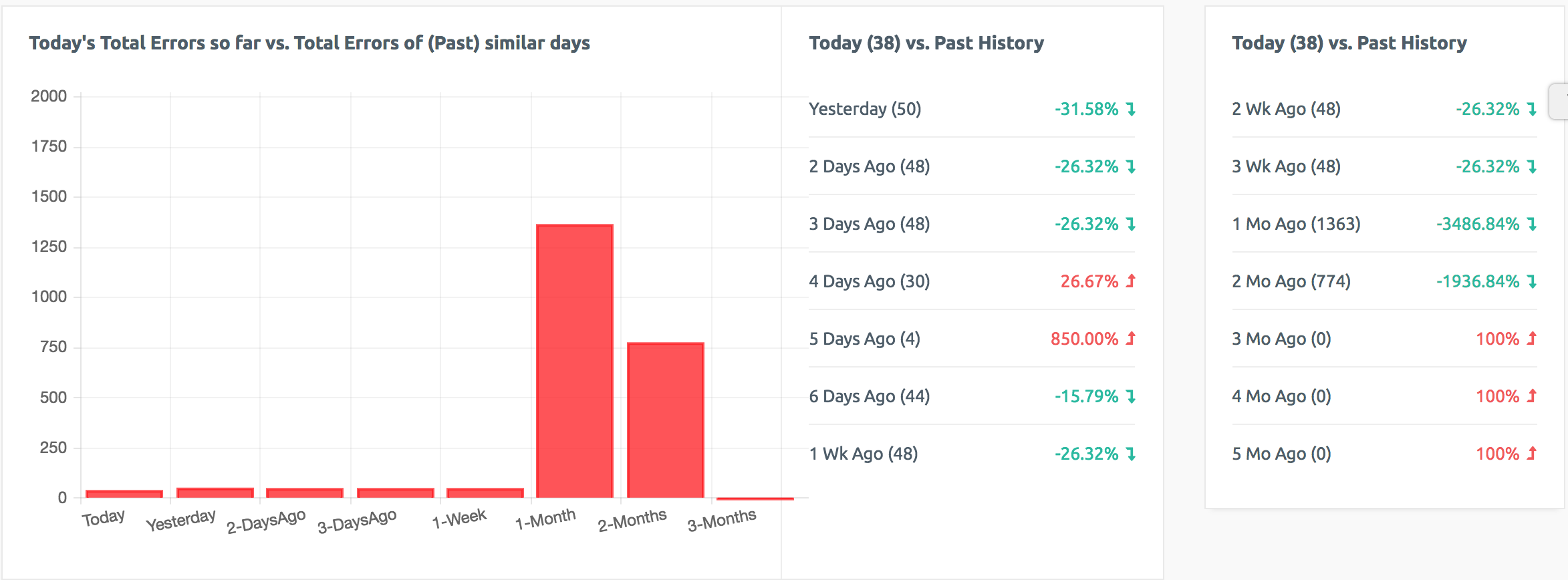
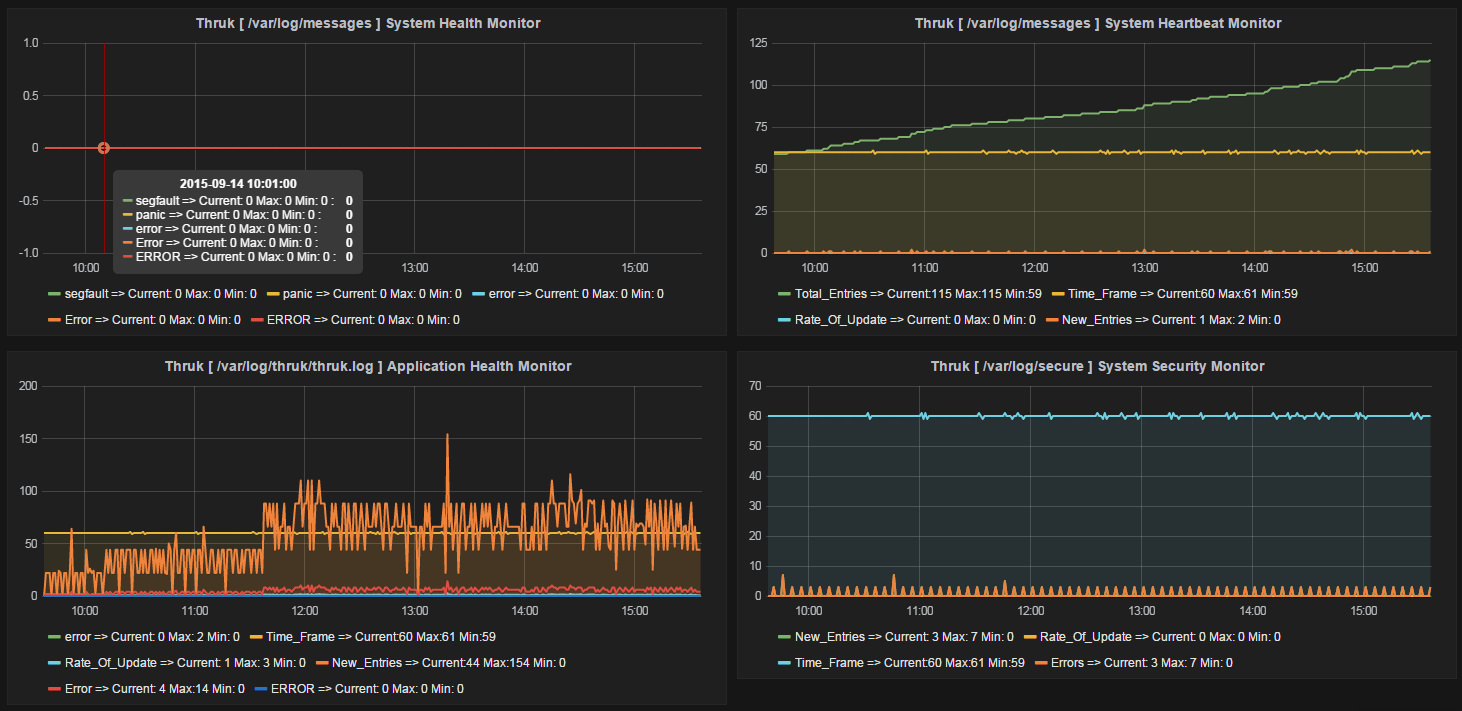
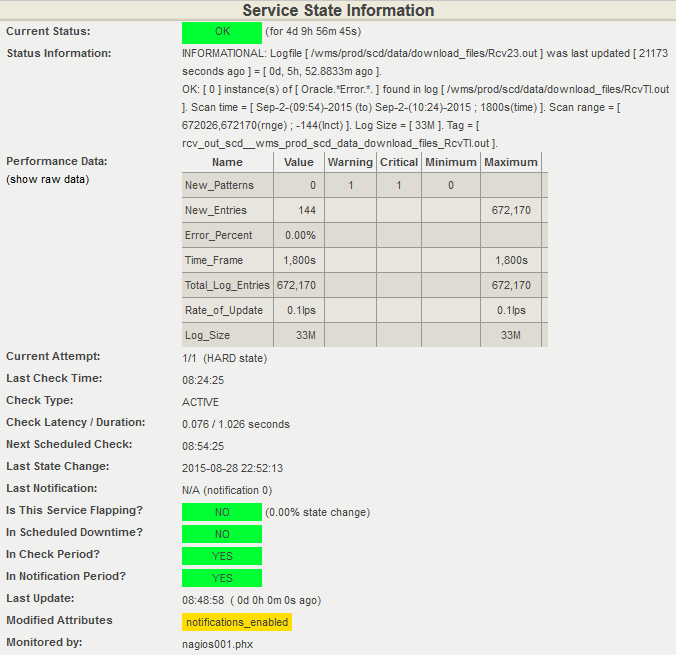
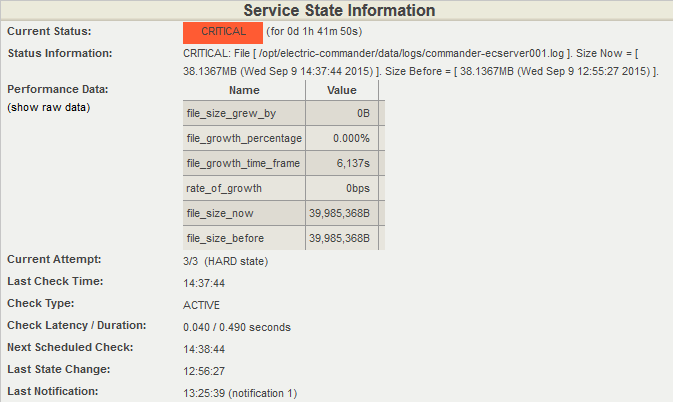
This is where the superiority of LoGrobot comes into play. LoGrobot is a commercial Log Monitoring utility that is very easy to utilize. It is robust, seasoned and efficiently versatile like no other tool. It understands the overriding significance of log alerts and focuses on ensuring only valid notifications are generated for the log files it monitors. Installation wise, LoGrobot does not require the addition of any nonnative modules or libraries to the system. Which means, you can install it freely on production/dev/qa servers without tampering with existing libraries or modules.
LoGrobot has a wide range of capabilities. It isn't limited to just scanning log file contents for errors. It can do virtually anything as long as it falls under the banner of log monitoring. Additionally, LoGrobot has years of real life situations, scenarios, possibilities and conditions built into it, which basically means it is highly unlikely you will come up with a need that hasn't already been thought of and programmed into the tool. In the unlikely event that does happen, chances are, work is already in progress to address it.
When it comes to keeping an unwavering eye on all important log files in your UNIX environment, you need ONE log monitoring tool, and LoGrobot is that tool!

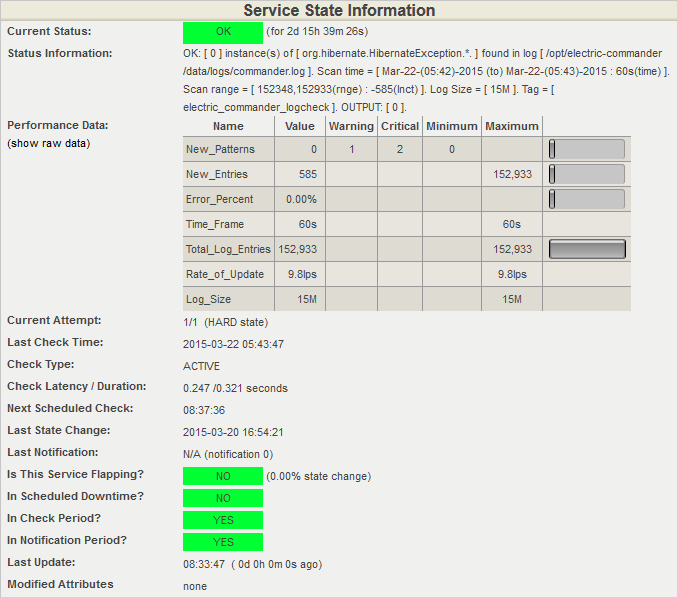
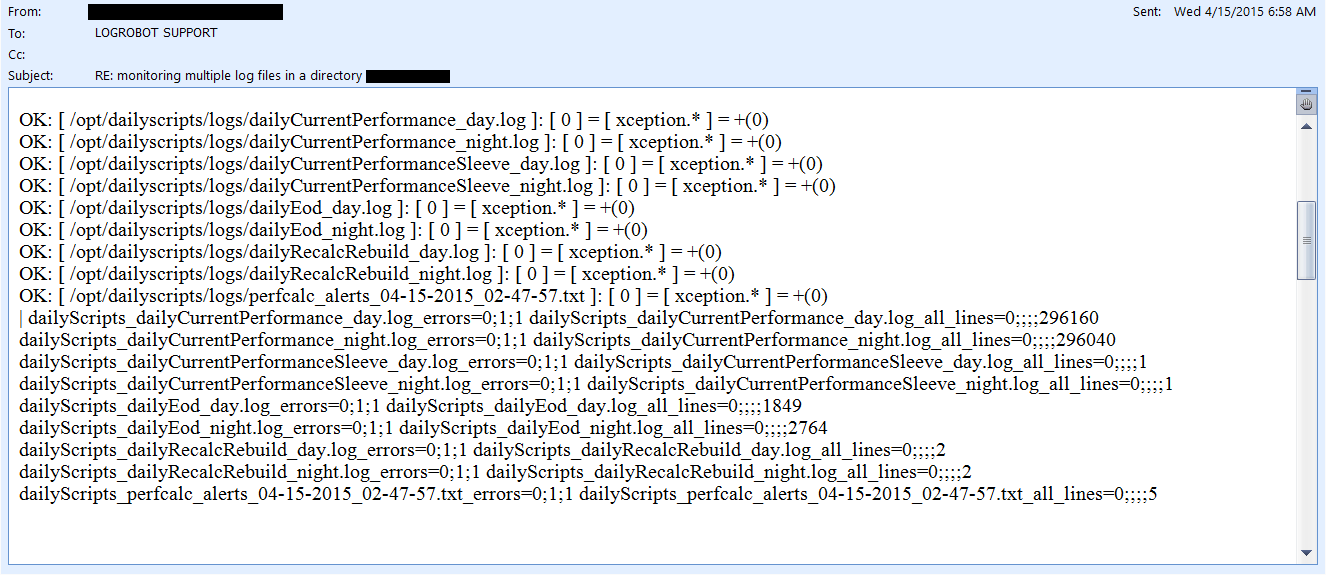
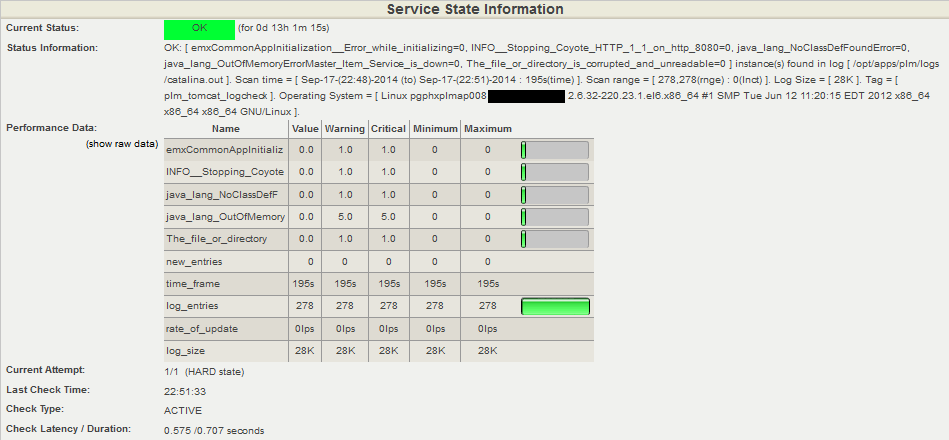
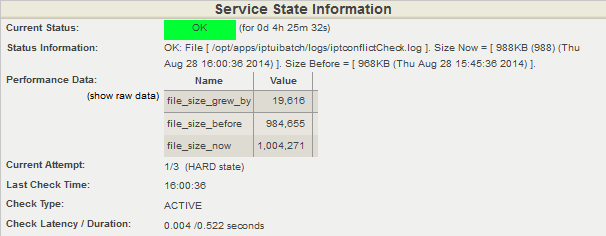
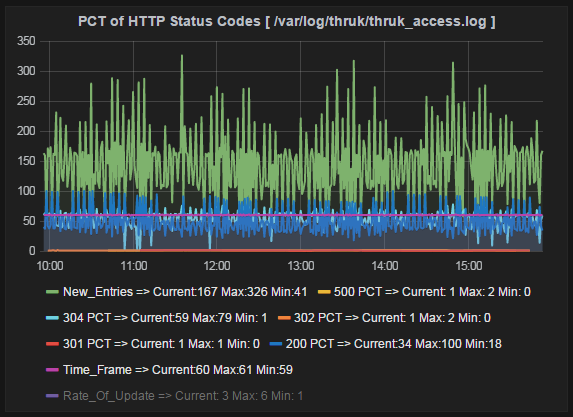


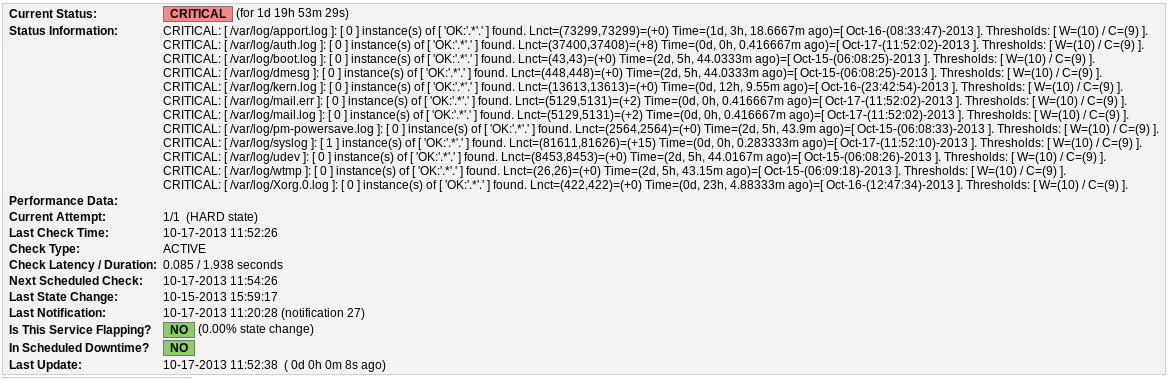
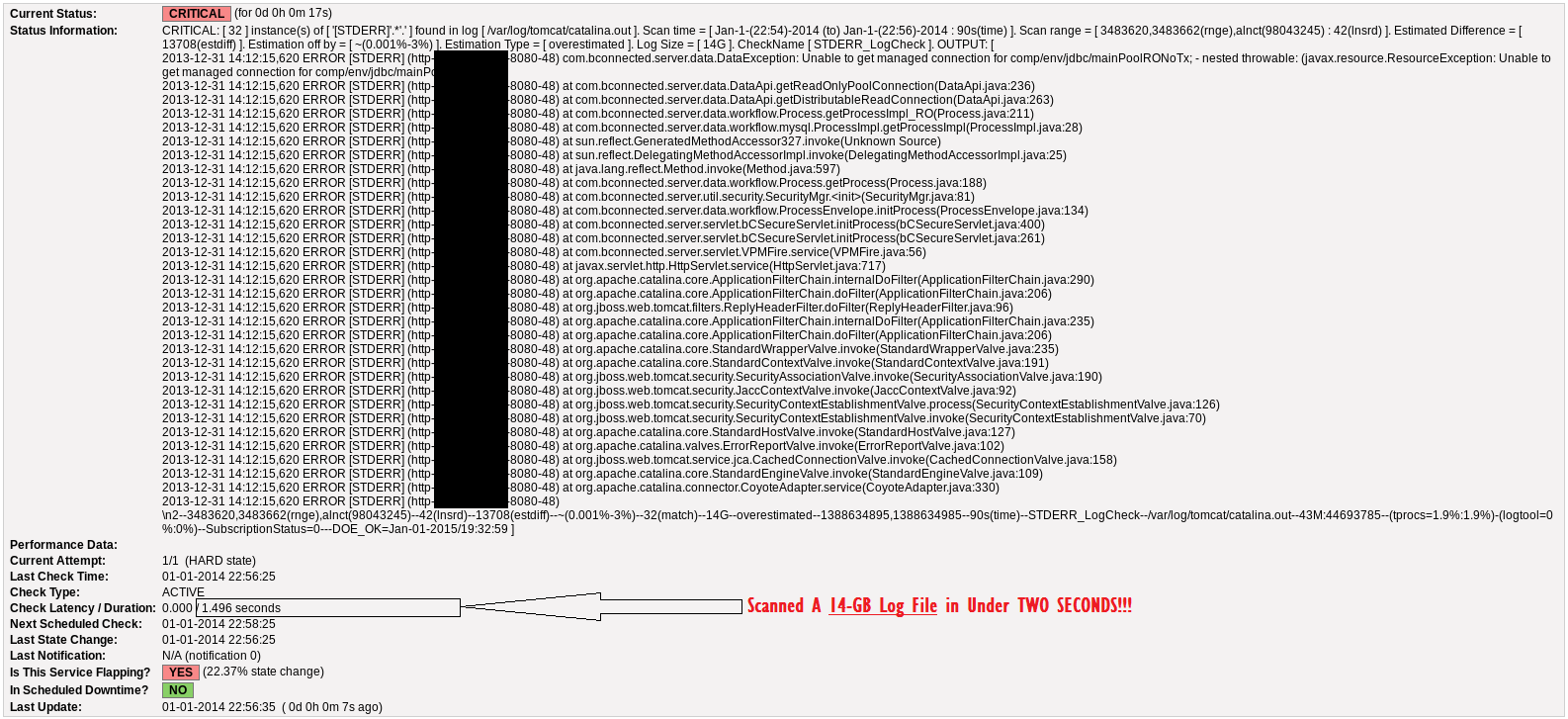
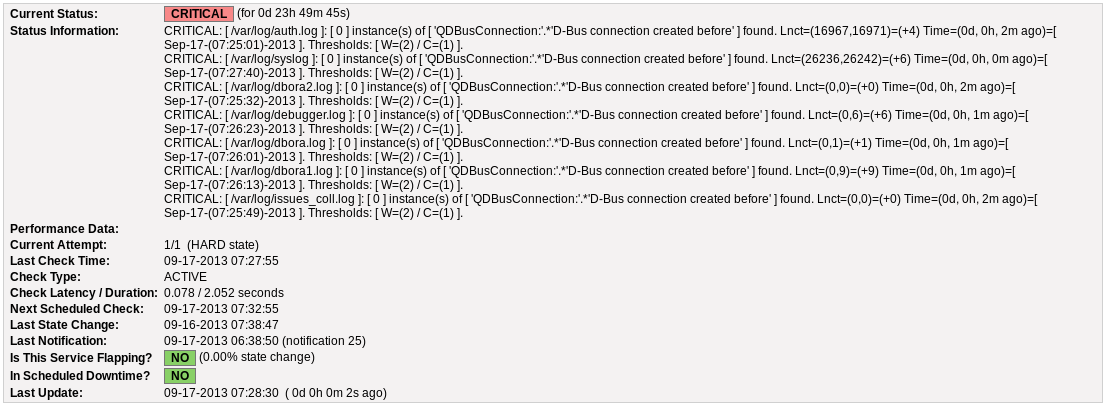

){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}